
Hidayat Tri Winasis
15 Oktober 2024
This project aims to estimate consultation fees for doctors based on several key factors, including the doctor's qualifications, location of practice, specialization, and years of experience in the field. The model will provide valuable insights for hospitals, doctors, and patients. Hospitals can use the model to set competitive fees aligned with market standards and determine fair compensation for doctors. For doctors, it offers a framework to set appropriate fees that reflect their expertise. Patients, in turn, will benefit from clearer information regarding consultation fees, allowing them to make informed decisions and ensuring that they pay prices that correlate with the quality of care they receive.
The healthcare sector is constantly evolving, and understanding how to establish appropriate consultation fees is crucial for all stakeholders. With varying levels of experience and qualifications among doctors, setting fair prices can be challenging. A data-driven approach to predict these fees can facilitate transparency and fairness in the healthcare market. The need for accurate fee estimations has become even more urgent in recent years, especially as the healthcare industry adapts to changing economic conditions. Hospitals and doctors must navigate competitive environments while ensuring that patients receive fair pricing, making a robust prediction model essential to address these challenges.
The primary goal of this project is to create a doctor fees prediction model using machine learning techniques. By the end of this article, insights into the methodology used and the model's performance will be presented, demonstrating how such a model can enhance decision-making in setting consultation fees.
The dataset for this project was sourced from Kaggle, specifically the Doctor Fees Prediction dataset. This dataset provides detailed information about doctors and their consultation fees across various regions in India. It offers a comprehensive view of the key factors influencing consultation fees, such as qualifications, years of experience, doctor ratings, location, and specialization.
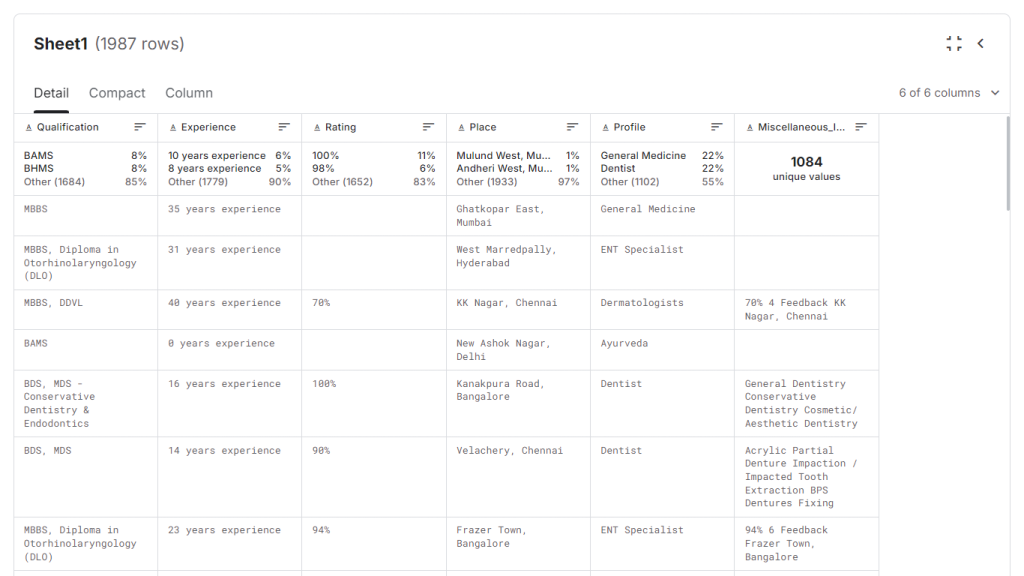
The following provides explanations for each feature in the dataset:
By analyzing these features, we can identify patterns and relationships between a doctor’s qualifications, experience, and other factors, and how they contribute to the consultation fee charged. The dataset provided an excellent foundation to build a robust prediction model, even though it's limited to the Indian healthcare context.
Before building the model, several data preprocessing steps were undertaken to prepare the dataset for analysis. First, data cleaning was performed by removing string values and extracting numerical information to ensure consistency across the dataset. Categorical variables, such as doctor’s specialization and location, were then transformed into numerical values using one-hot encoding, allowing them to be used effectively in the model. Missing values were handled by filling them with the mean of the respective columns. Lastly, a log transformation was applied to the target variable, consultation fees, using np.log to normalize its distribution.
Before building the model, several data preprocessing steps were undertaken to prepare the dataset for analysis. First, data cleaning was performed by removing string values and extracting numerical information to ensure consistency across the dataset. Categorical variables, such as doctor’s specialization and location, were then transformed into numerical values using one-hot encoding, allowing them to be used effectively in the model. Missing values were handled by filling them with the mean of the respective columns. Lastly, a log transformation was applied to the target variable, consultation fees, using np.log to normalize its distribution.
The table below summarizes the MSE and MAE results for each model.
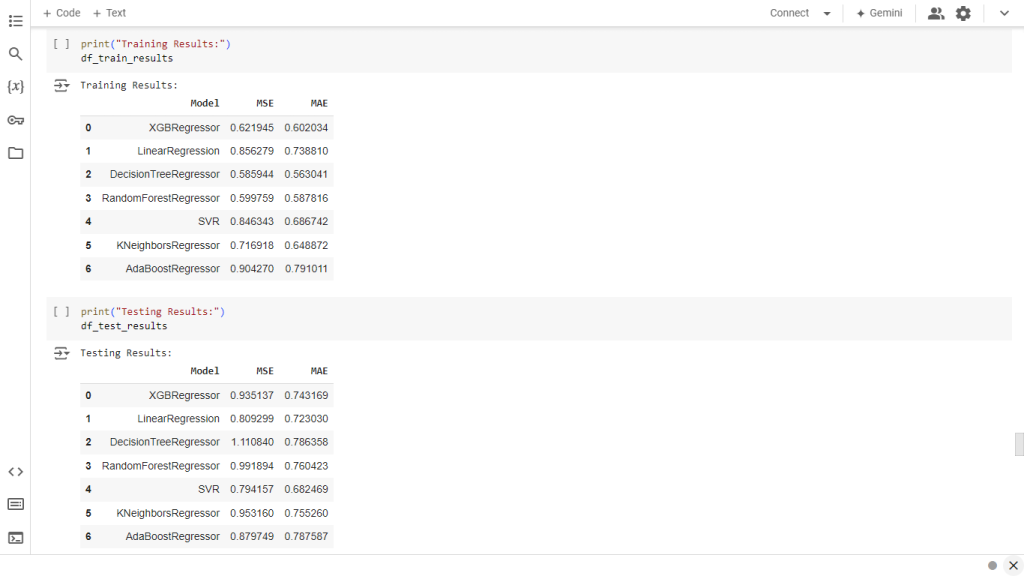
After training the models on the dataset and evaluating their performance using MAE & MSE, the XGBoost Regressor was selected as the final model. There were several reasons for choosing XGBoost: First, it exhibited robust performance metrics, achieving low values for both MSE and MAE, indicating its accuracy in predicting consultation fees. Additionally, XGBoost effectively handles complex, non-linear relationships, and is optimized for speed and performance, making it an excellent choice for a dataset that includes thousands of records.
The performance of the XGBoost model was assessed on both training and testing datasets using two key metrics: Mean Squared Error (MSE) and Mean Absolute Error (MAE). Below are the results and their interpretations:
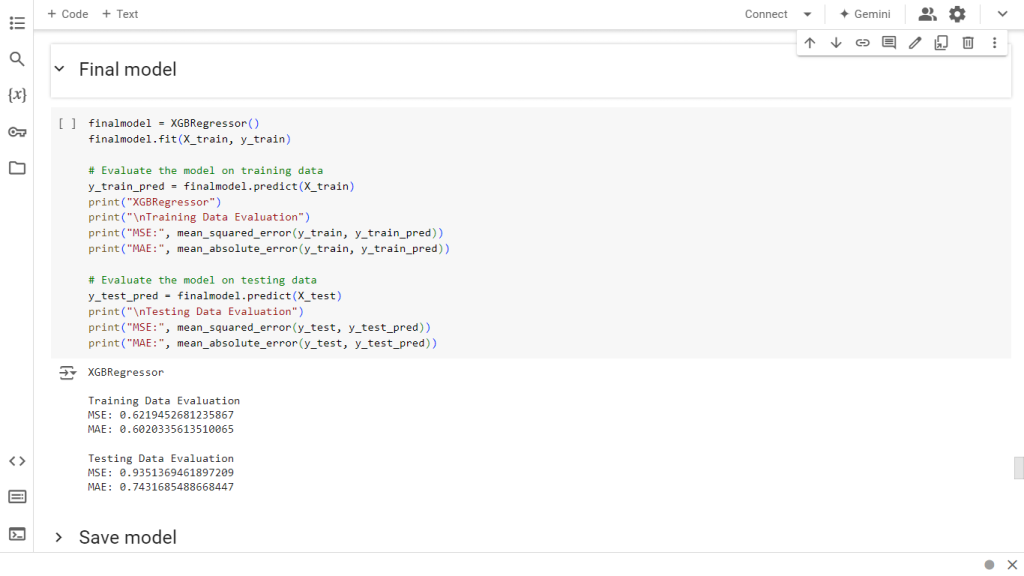
On the training data, the model achieved an MSE of 0.6219 and an MAE of 0.6020, while on the testing data, the MSE was 0.9351 and the MAE was 0.7432. These results demonstrate that the XGBoost model performs well across both training and testing sets, with both MSE and MAE values remaining within acceptable ranges. The low MSE indicates that the model successfully minimizes large prediction errors, which is particularly important in avoiding significant deviations from actual consultation fees that could result in inaccurate pricing. The MAE results further reveal that, on average, the model's predictions are off by only 0.60 to 0.74 units of consultation fees, showcasing its precision. Additionally, the small difference between training and testing errors suggests the model generalizes effectively to new data without overfitting, making XGBoost a strong and reliable choice for predicting doctor fees based on the given features.
The deployment process began by creating a GitHub repository to house essential files, including app.py (the main application script) and model.pkl (the serialized XGBoost model). A Python environment was set up with essential libraries like Streamlit and XGBoost. The app.py script was developed to manage user inputs and model predictions, while the trained model was serialized using Pickle for efficient loading. Afterward, the application was deployed to Streamlit Cloud by linking the GitHub repository, enabling users to access the live application.
The Streamlit application is now live and can be accessed here. Users will encounter a simple interface to input essential variables including qualifications, location, specialization, and experience. After entering the details and clicking the Predict button, the model will generate a predicted consultation fee based on the provided data.
In summary, the project successfully developed a predictive model for doctor consultation fees using XGBoost, which was deployed as a user-friendly application on Streamlit. The model exhibited strong performance, with low MSE and MAE values, demonstrating its reliability in estimating fees based on specialization, location, and experience. By providing valuable insights, the model enables hospitals to set competitive pricing, assists doctors in determining fair consultation fees, and informs patients about expected costs, thereby fostering a more transparent and equitable healthcare pricing system. Future work may involve exploring Indonesian datasets to enhance the model's relevance in local contexts.
Artikel Lainnya

Cheva Wahyu Noerhuda
10 September 2024
Library Python gTTS untuk Pemanggilan Antrian

Eriko Syah Putra Friyadi
16 Oktober 2024
Sistem Rekomendasi Makanan Berdasarkan Nutrisi

Risma Dhiya Ulhaq M.
22 Oktober 2024
Health Reccomendation System

Dengan teknologi yang adaptif dan solusi yang inovatif, kami siap membantu bisnis Anda meraih potensi terbaiknya.

AD Premier Lantai 17 Suite 04 B, Jl. TB. SImatupang No. 5 Desa/Kel. Ragunan, Kec. Pasar Minggu, Kota ADM. Jakarta Selatan.
Perum D Livia Gading No. 3, Kel. Kalisegoro, Kec. Gunungpati, Kota Semarang
copyright Serpihan Tech Solution © 2024 - All Right Reserved